
ICLR 2021
Published:
ICLR 2021
Table of Contents
- Commonsense AI: Myth and Truth
- WHEN DO CURRICULA WORK
- RETHINKING ATTENTION WITH PERFORMERS
- DeLighT: Deep and Light-weight Transformer
- Are wider nets better given the same number of parameters?
- The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers
- PMI-MASKING: PRINCIPLED MASKING OF CORRELATED SPANS
Commonsense AI: Myth and Truth
By Yejin Choi
In this talk, Yejin mainly talks about abduction and counterfactual reasoning and mentions that although they’re different, both involve nonmonotonic reasoning with past context X and future constraint Z.

Picture taken from the slides
Using language models such as GPT2 bc they are only good at conditioning on the past and we can incorporate the future by incorporating both past and future as the past with a special token in between. But this doesn’t generalize well to out-of-domain distribution. So they propose to use back-prop as an inference time algorithm rather than training time only for abduction. For counterfactual reasoning, the same works just need to change the loss function to K-L divergence. Perhaps the image below is more clear
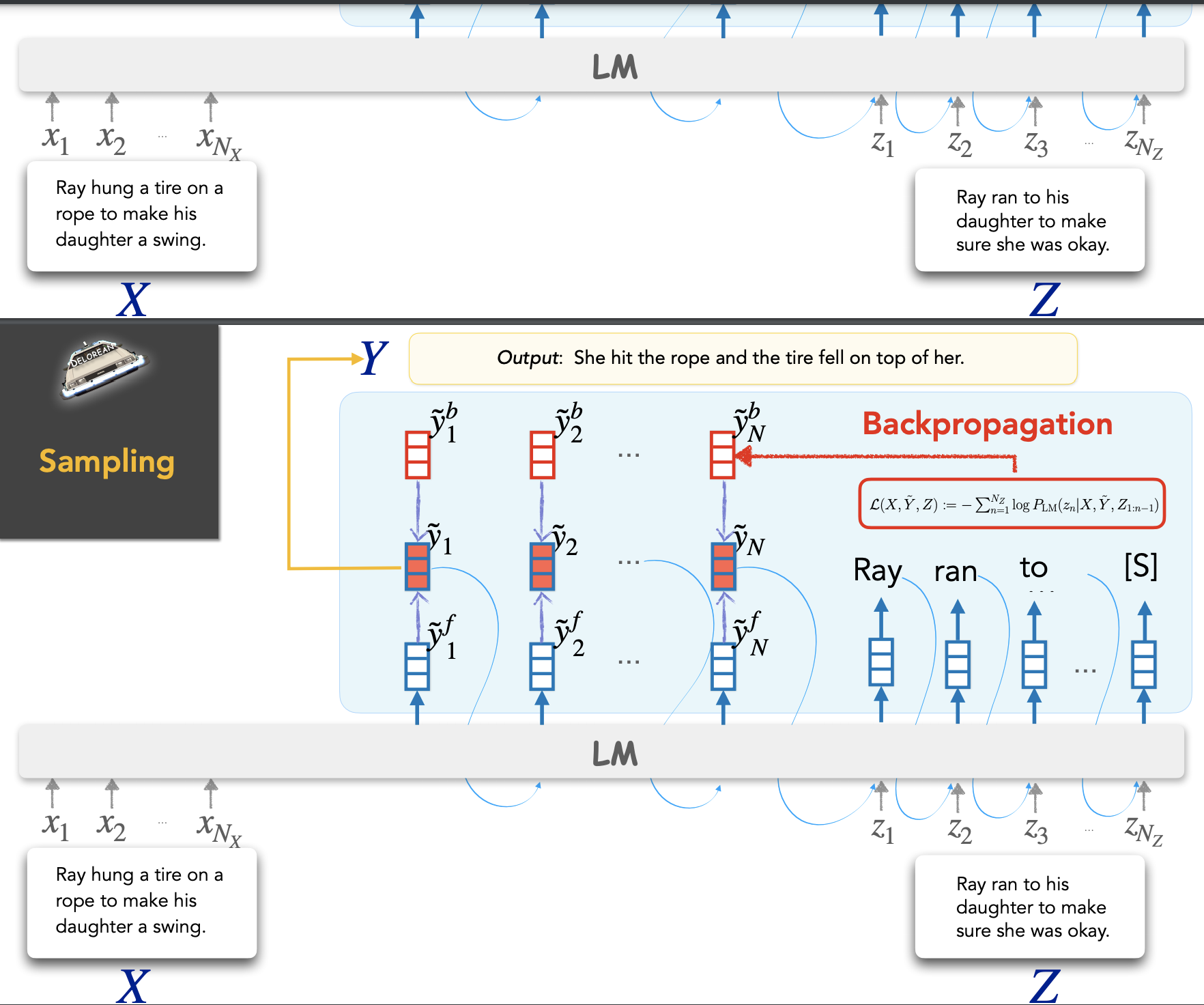
Image taken from the slides
Knowledge and reasoning:
The Off-the-shelf language models are not equivalent to knowledge models, and we need to build knowledge models if we want to do reasoning. COMET is the common sense knowledge graph that has 1.33 M commonsense if-then inferences over 23 relations (or inference time). Comet is at least 400 times smaller than GPT3 and still, COMET outperforms GPT3 and COMET in common sense reasoning and COMET generalizes well on out-of-domain examples.
Key take away message: A lot of commonsense reasoning might require the full scope of language and the distinction between knowledge and reasoning is blurry and there’s and we need natural language for reasoning since there is no way we can represent the complexity of commonsense in clean-cut logical forms.
WHEN DO CURRICULA WORK
Authors: Xiaoxia Wu, Ethan Dyer, Behnam Neyshabur
They examined whether the curriculum learning works or not. In order to do that, they first define the notion of difficulty for each example. The difficulty of each sample is defined by its learned iteration. Learned iteration is the iteration at which the sample is classified correctly and also in all the later iterations that sample is classified correctly as well. They sort the data based on the learned iteration and define a window of size k. Then they compare the performance of standard training with curriculum learning, anti-curriculum learning, and random learning (they shuffle the data, but a sample from each window of size k one by one). They observed: Curricula achieve (almost) no improvement in the standard-setting. They show curriculum learning, random, and anti-curriculum learning perform almost equally well in the standard-setting Curriculum learning improves over standard training when training time is limited. Imitating the large data regime, where training for multiple epochs is not feasible, They limit the number of iterations in the training algorithm and compare curriculum, random and anti-curriculum ordering against standard training. Our experiments reveal a clear advantage of curriculum learning over other methods. Curriculum learning improves over standard training in a noisy regime. Finally, They mimic noisy data by adding label noise to CIFAR100. Our experiments indicate that curriculum learning has a clear advantage over other curricula and standard training.
RETHINKING ATTENTION WITH PERFORMERS
Authors: Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Quincy Davis, Afroz Mohiuddin, Lukasz Kaiser, David Benjamin Belanger, Lucy J Colwell, Adrian Weller
traditional attention-based models are not scalable since attention has quadratic time and space complexity. This paper introduces the performer, at efficient attentions base model. Performer provides linear space and time complexity without any assumption needed (such as sparsity or low-rankness). To approximate softmax attention kernels, Performers use a novel Fast Attention Via positive Orthogonal Random features approach (FAVOR+) which approximates the standard attention weights. FAVOR is fully compatible with regular Transformers and the authors show theoretically that FAVOR guarantees unbiased or nearly-unbiased estimation of the attention matrix, uniform convergence, and low estimation variance.
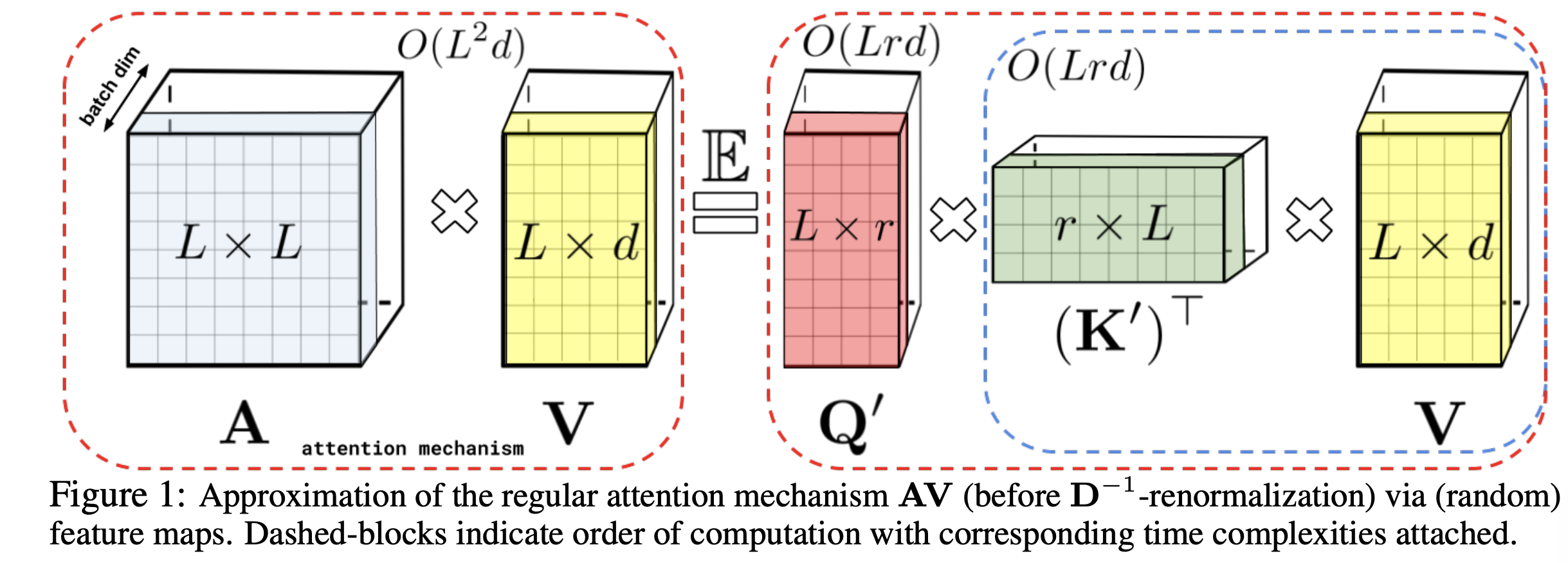
Image taken from the paper
See the paper for more details of how FAVOR works by decomposing each attention matrix in each batch into two matrices Q and K and their properties.
DeLighT: Deep and Light-weight Transformer
Authors: Sachin Mehta, Marjan Ghazvininejad, Srinivasan Iyer, Luke Zettlemoyer, Hannaneh Hajishirzi
In order to learn deeper and wider representation, linear layers are used which allows to learn global representation. In order to improve the efficiency, the authors proposed to divide the input into two groups and then for each group, apply linear transformation into each group independently. In this manner, the number of parameters is reduced while the model still learns local representation within each group and not t. To allow global representation learning, the authors suggest feature shuffle. After applying one linear transformation to each group independently, the features are shuffled and then group linear transformation. With this model, the model learns both global and local representation. In addition to feature shuffle, the authors used the input mixer connection to avoid vanishing radiant decent problem, improve stability in training, and also improving performance while increasing depth (without input mixer connection, authors observe the model gets worse when increasing the depth).
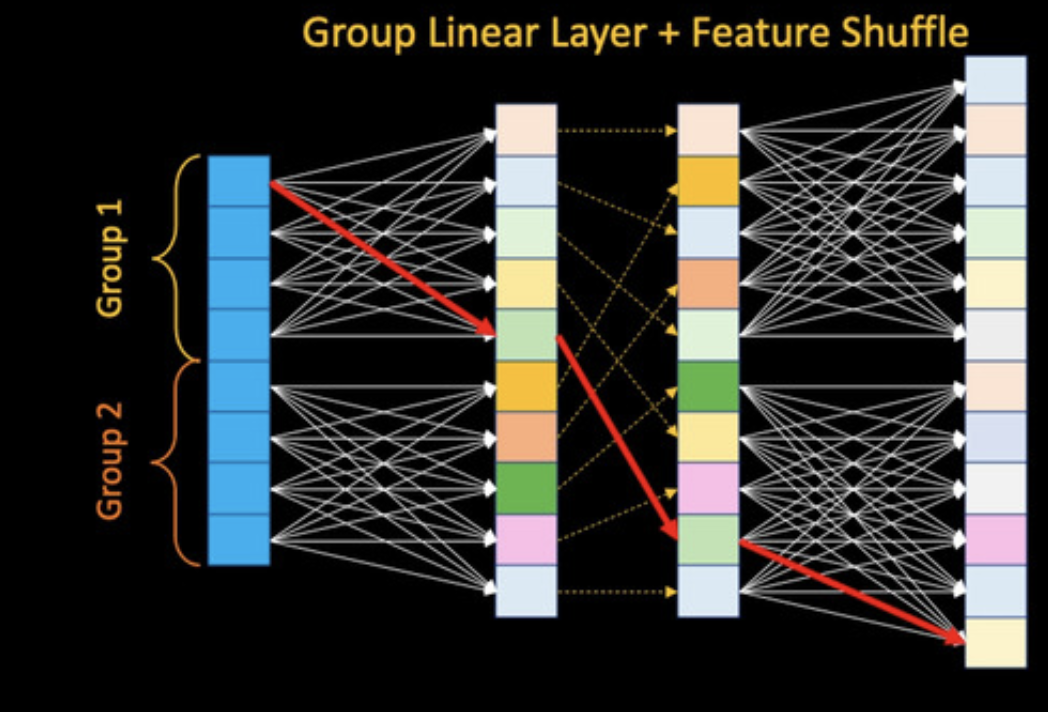
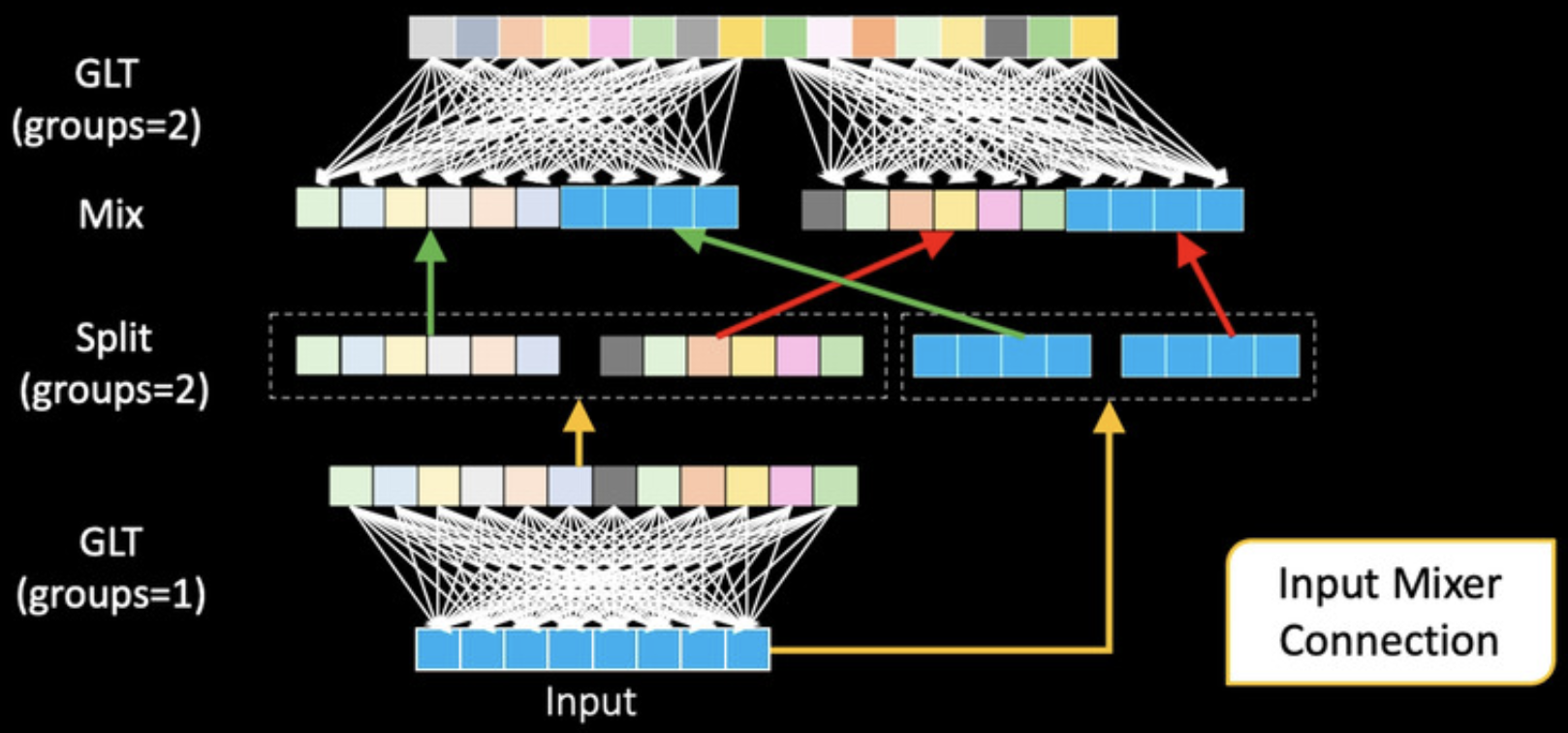
Image taken from the paper
Are wider nets better given the same number of parameters?
Authors: Anna Golubeva, Guy Gur-Ari, Behnam Neyshabur
They showed that when fixing the size of the model (and the number of parameters), while increasing the width of the model, the model performance improves. More specifically, they showed They observed that for ImageNet, increasing the width (by Setting some weights to zero using a mask that is randomly chosen) leads to almost identical performance as when they allow the number of weights to increase along with the width. To understand the observed effect theoretically, authors study a simplified model and show that the improved performance of a wider, sparse network is correlated with a reduced distance between its Gaussian Process kernel and that of an infinitely wide network. Authors propose that reduced kernel distance may explain the observed effect
The Deep Bootstrap Framework: Good Online Learners are Good Offline Generalizers
Authors: Preetum Nakkiran, Behnam Neyshabur, Hanie Sedghi
They propose a new framework, deep bootstrap, to study generalization in deep learning. Where in real-world where SGD takes step in empirical loss and in the ideal world, SGD, takes steps in population loss (and hence train loss = test loss). The ideal world is a world when there exists infinite labeled data hence when they increase the steps, they’ll see new data points and they don’t have to see a sample multiple times during training. They show that The generalization of models is largely determined by their optimization speed in online and offline learning. They claim the real world is equivalent to the ideal world as long as the ideal world hasn’t converged yet. They also claim good models and training procedures are those which (1) optimize quickly in the Ideal World and (2) do not optimize too quickly in the Real World.
PMI-MASKING: PRINCIPLED MASKING OF CORRELATED SPANS
Authors: Yoav Levine, Barak Lenz, Opher Lieber, Omri Abend, Kevin Leyton-Brown, Moshe Tennenholtz, Yoav Shoham
Instead of masking tokens randomly in Transformers which is suboptimal, the authors propose PMI-Masking, which is based on the concept of Pointwise Mutual Information (PMI), which jointly masks a token n-gram if it exhibits high collocation over the corpus. They showed that (1) PMI-Masking dramatically accelerates training, matching the end-of-pretraining performance of existing approaches in roughly half of the training time; and (2) PMI-Masking improves upon previous masking approaches at the end of pretraining.