
Edge Probing
Published:
In the past couple of years, Transformers has acheived state of art results in a variety of natural language tasks. In order to better understand Transformers and what they are learning in practice, researchers have done layer-wise analysis of Transformer’s hidden states to understand what the Transformer is learning in each layer. A wave of recent work has started to “prob” the state of the art Tranformers to inspect the structure of the network to assess whether there exist localizable regions associated with distinct types of linguistic decisions, both syntactic and semantic information. Researchers examine the hidden states between encoder layers directly and use those hidden states in a linear layer + softmax to predict what kind of information in encoded in each hidden state.
For example, in the paperHow Does BERT Answer Questions?, a BERT model is trained on Question Answering (QA) as QA is one of such tasks that require a combination of multiple simpler tasks such as Coreference Resolution and Relation Modeling to arrive at the correct answer. After the model is trained, a layer-wise visualisation of token representations is provided in which the visualiztion reveals information about the internal state of Transformer networks.
In the figure below, you can see the overview of the BERT architecture and the probing setup. The hidden states of each layer as input to a set of probing tasks to examine the encoded information.
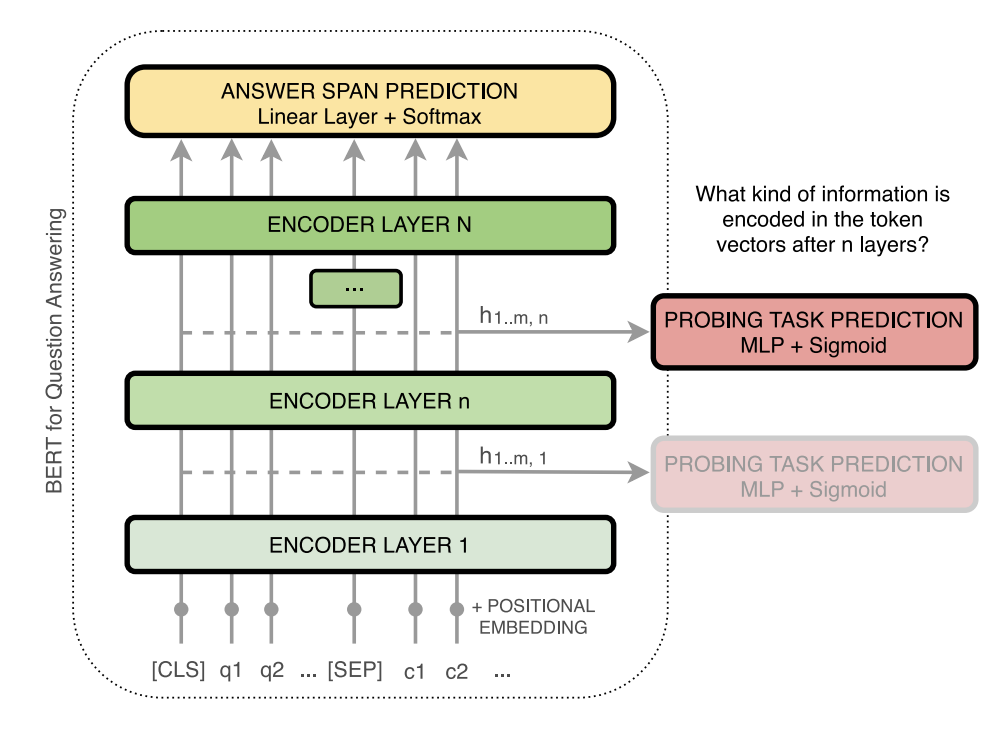 Picture taken from the paper, How Does BERT Answer Questions?
Picture taken from the paper, How Does BERT Answer Questions?
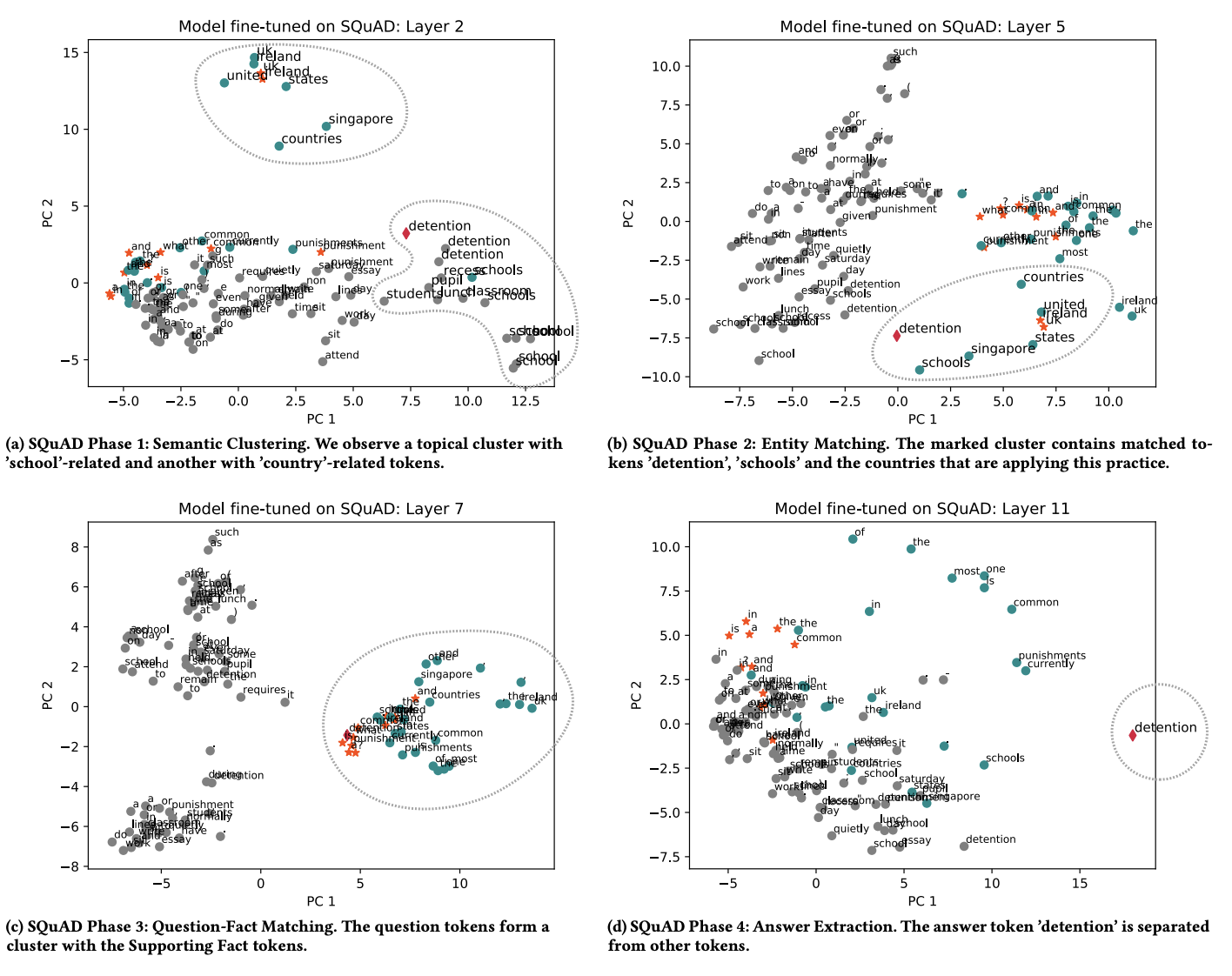
In order to visualize the token representaion in each layer, authors use dimensionality reduction + K-means Clustering. For dimensionality reduction, they apply T-distributed Stochastic Neighbor Embedding (t-SNE), Principal Component Analysis (PCA) and Independent Component Analysis (ICA) to vectors in each layer. Then for clustering, they choose number of clusters k in regard to the number of observed clusters in PCA. In the figure below, you can see the visualization of each layer of the BERT model trained on the SQUAD dataset. As illustrated in the figure, the early layers within the BERT-based models group tokens into topical clusters., resulting vector spaces are similar in nature to embedding spaces from e.g. Word2Vec and hold little task-specific information. Therefore, these initial layers reach low accuracy on semantic probing tasks, BERT’s early layers can be seen as an implicit replacement of embedding layers common in neural network architectures. These lower layers of a language model encode more local syntax rather than more complex semantics. In the middle layers of the observed networks we see clusters of entities that are less connected by their topical similarity. Rather, they are connected by their relation within a certain input context. These task-specific clusters appear to already include a filtering of question-relevant entities. Figure belowe (b) shows a cluster with words like countries, schools, detention and country names, in which ’detention’ is a common practice in schools. This cluster helps to solve the question “What is a common punishment in the UK and Ireland?”.
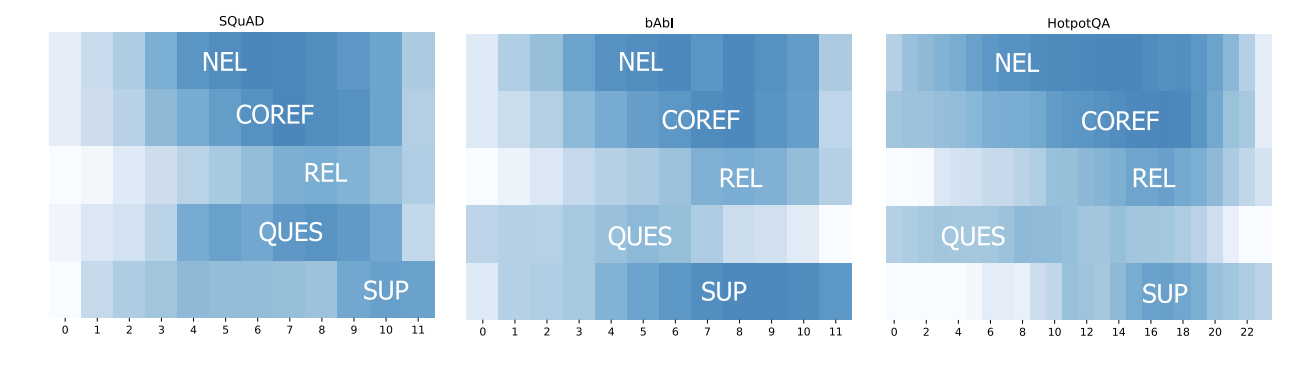
In short, the authors observed the model’s ability to recognize entities (Named Entity Labeling), to identify their mentions (Coreference Resolution) and to find relations (Relation Recognition) improves until higher network layers. The figire below visualizes these abilities. Information about Named Entities is learned first, whereas recognizing coreferences or relations are more difficult tasks and require input from additional layers until the model’s performance peaks.
References
- A Structural Probe for Finding Syntax in Word Representations
- BERT Rediscovers the Classical NLP Pipeline
- Deconstructing BERT
- WHAT DO YOU LEARN FROM CONTEXT? PROBING FOR SENTENCE STRUCTURE IN CONTEXTUALIZED WORD REPRESENTATIONS
- How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations
- Finding Syntax with Structural Probes
- Probing What Different NLP Tasks Teach Machines about Function Word Comprehension
- TOWARD UNDERSTANDING TRANSFORMER BASED SELF SUPERVISED MODEL