
Transformers 2
Published:
This blog post is the continuation of my previous blog post, Transformers. In my previous blog post, I explained original Transformer paper, BERT, GPT, XLNet, RoBERTa, ALBERT, BART, and AMBER. In this blog post, I will explain MARGE, ConveRT, Generalization through Memorization, AdapterHub, and T5. Images and content used in this blogpost, otherwise mentioned, are all taken from the papers on each model.
Table of Contents
- Pre-training via Paraphrasing - MARGE (Multilingual Autoencoder that Retrieves and Generates
- ConveRT: Efficient and Accurate Conversational Representations from Transformers
- Generalization through Memorization: Nearest Neighbor Language Models
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, T5
- AdapterHub: A Framework for Adapting Transformers
Pre-training via Paraphrasing - MARGE (Multilingual Autoencoder that Retrieves and Generates
Paper from Facebook AI
Presenation in ACL 2020, “Beyond BERT” by Mike Lewis 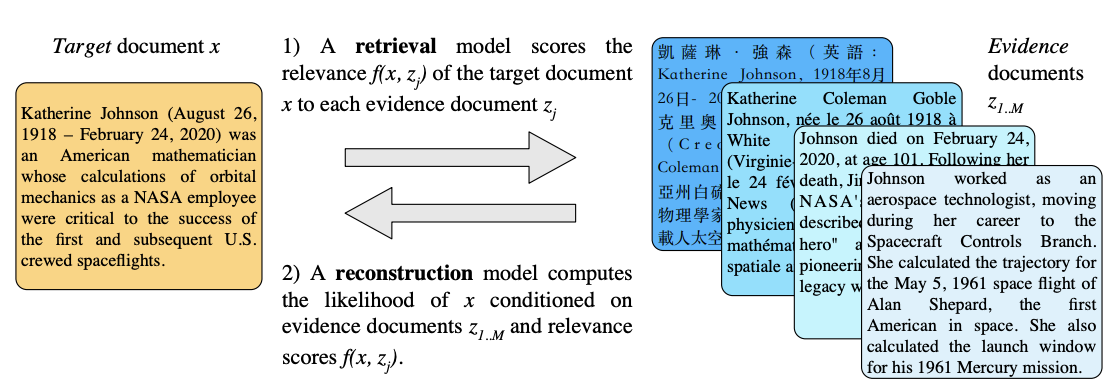
In this paper, authors tried grounding natural language into the reality of our world instead of MLM. The problem with next token predictions MLM is that they focus only on linguistic form, they learn the characteristics of coherent language without necessarily associating meaning to it.
MARGE is a pre-trained sequence-to-sequence model learned with an unsupervised multilingual multi-document paraphrasing objective. During pre-training, the input to the model is a batch of evidence documents z1..M and target documents x1..N . The model is trained to maximize the likelihood of the targets, conditioned on the evidence documents, and the relevance of each evidence document to each target:
- The model first computes a relevance score f(xi , zj ) between every pair of documents xi and zi , by embedding each document and computing their cosine similarities.
- The model then computes the likelihood of reconstructing each xi conditioned on z1..M and each f(xi , ·), using a modified seq2seq model. The similarity score encourages the model to attend more to relevant evidence documents. Backpropagating the reconstruction loss therefore improves both the sequence-to-sequence model and the relevance model.
- They construct batches so that evidence documents are relevant to the targets, using the relevance model for retrieval
A truly remarkable outcome is that MARGE can perform decent zero-shot machine translation that is, without any fine-tuning on parallel data
ConveRT: Efficient and Accurate Conversational Representations from Transformers
Paper by PolyAI
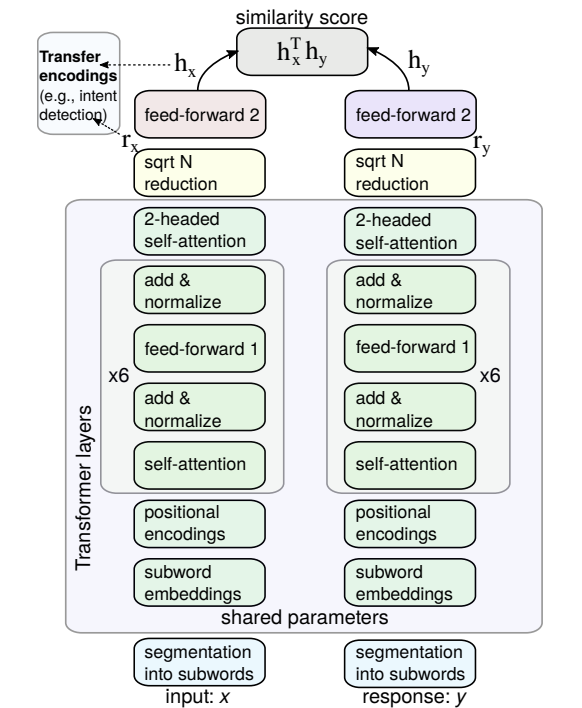
They used shared parameters, quantization and less number of layers, but instead used a very long sequence input (for conversation it’s needed) and reduced the number of parameters by order of magnitude.
Generalization through Memorization: Nearest Neighbor Language Models
Paper from Facebook AI and Stanford
Presenation in ACL 2020, “Beyond BERT” by Mike Lewis
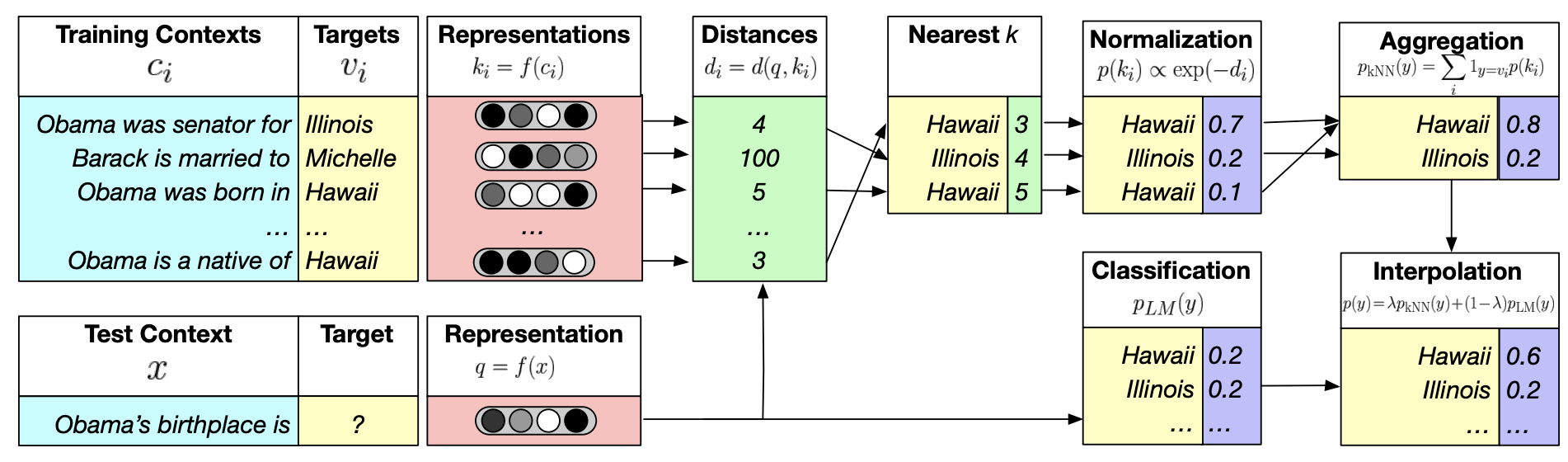
The main contribution: Improvement for downstream tasks which need factuality like QA The paper introduces kNN-LM, an approach that extends a pre-trained LM by linearly interpolating its next word distribution with a k-nearest neighbors (kNN) model. The nearest neighbors are computed according to distance in the pre-trained embedding space and can be drawn from any text collection, including the original LM training data. This approach allows rare patterns to be memorized explicitly, rather than implicitly in model parameters. It also improves performance when the same training data is used for learning the prefix representations and the kNN model, strongly suggesting that the prediction problem is more challenging than previously appreciated.
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, T5
Paper from Google 
With T5, authors propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. The text-to-text framework allows to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). One can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself. Fidnings:
- model architectures, where they found that encoder-decoder models generally outperformed “decoder-only” language models;
- pre-training objectives, where they confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost;
- unlabeled datasets, where they showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- training strategies, where they found that multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task;
- and scale, where they compare scaling up the model size, the training time, and the number of ensembled models to determine how to make the best use of fixed compute power.
AdapterHub: A Framework for Adapting Transformers
Paper from Technical University Darmstadt, New York University, CIFAR, University of Cambridge,DeepMind
AdapterHub enables you to perform transfer learning of generalized pre-trained transformers such as BERT, RoBERTa, and XLM-R to downstream tasks such as question-answering, classification, etc. using adapters instead of fine-tuning. Adapters serve the same purpose as fine-tuning but do it by stitching in layers to the main pre-trained model, and updating the weights Φ of these new layers, whilst freezing the weights θ of the pre-trained model. As you might imagine, this makes adapters much more efficient, both in terms of time and storage, compared to fine-tuning. Adapters have also been shown to be able to match the performance of state-of-the-art fine-tuning methods!