
Text Summarization
Published:
Automatic summarization is the process of shortening a set of data computationally, to create a subset (a summary) that represents the most important or relevant information within the original content. Text summarization finds the most informative sentences in a document.
Here is also my Colab notebook on fine tuning T5 model for summarization task using Trenasformers + PyTorch Lightning
Table of Contents
Strategies for generating summaries
Therea are two general approches to text summarziation:
- extractive summarization, where salient spans of text are identified as important segments and directly copied into the summary (similar to highlighting text with a marker).
- abstractive summarization, where the generated summary is a paraphrased of the important part of the text and hence more similar to human-generated summaries
- Hybrid models, combines extractive and abstractive summarization and include two phases, content selection, and paraphrasing.
Prior to the hype of deep learning, TextRank and LexRank were two popular methods for extractive summarization. TextRank was mainly used for a single document and LexRank was mainly used for multi-document summarization. Both TextRank and LexRank create a graph of sentences and run the page rank algorithm to get the most important sentences (basically centroids in the graph). The edges between sentences are based on semantic similarity and content overlap. LexRank uses cosine similarity of TF-IDF vectors of sentences and TextRank uses the number of words two sentences have in common normalized by sentence length.
LexRank uses the score of sentences from the page rank algorithm as a feature in a larger system with other features such as sentence position, sentence length. source
Evaluation:
When training a model for summarization, one can use cross-entropy (similar to language modeling task) to train the model. The offline evaluation metrics are poorly correlated with human judgment and ignores important features such as factual correctness. The offline evaluation metrics can be categorized into the following groups.
n-GRAM Matching Metrics
ROUGE metric
ROUGE: A Package for Automatic Evaluation of Summaries ROUGE is the standard automatic evaluation measure for evaluating summarization tasks.
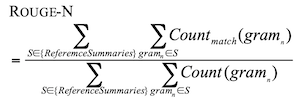
- Disadvantages:
- not suitable for abstractive summarization since it is based on n-gram overlaps. It expects the generated summary to be identical to the reference summary and does not recognize synonym concepts. It also doesn’t capture subset coverage (it focuses on the complete set of n-gram overlap).
- biased toward shorter summarizes
ROUGE-WE (R-WE)
Better Summarization Evaluation with Word Embeddings for ROUGE instead of hard lexical matching of bigrams, R-WE uses soft matching based on the cosine similarity of word embeddings.
ROUGE-G
A Graph-theoretic Summary Evaluation for ROUGE combines lexical and semantic matching by applying graph analysis algorithms to the WordNet semantic network
ROUGE 2.0
leverages synonym dictionaries, such as WordNet, and considers all synonyms of matched words when computing token overlap. ROUGE 2.0: Updated and Improved Measures for Evaluation of Summarization Tasks. To address ROUGE’s problems, the authors propose the following metrics:
ROUGE-{N|Topic|TopicUniq}+Synonyms
It captures synonyms using a synonym dictionary (synonym dictionary customizable by application and domain)
- ROUGE-Topic - topic or subset coverage (topic customizable by POS occurrence)
- ROUGE-TopicUniq- unique topic or subset coverage (topic customizable by POS occurrence)
METEOR
An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments based on a generalized concept of unigram matching between the machine produced translation and human-produced reference translations. Unigrams can be matched based on their surface forms, stemmed forms, and meanings; furthermore, METEOR can be easily extended to include more advanced matching strategies. Once all generalized unigram matches between the two strings have been found, METEOR computes a score for this matching using a combination of unigram-precision, unigram-recall, and a measure of fragmentation that is designed to directly capture how well-ordered the matched words in the machine translation are in relation to the reference.
Embedding Based Metrics
Distributional Semantics Reward (DSR)
Deep Reinforcement Learning with Distributional Semantic Rewards for Abstractive Summarization Given that contextualized word representations (such as ELMO, BERT, GPT) have shown that they have a powerful capacity of reflecting distributional semantic, the authors propose to use the distributional semantic reward to boost the reinforcement learning-based abstractive summarization system.
- Advantages:
- DSR does not rely on cross-entropy loss (XENT) to produce readable phrases. Thus, no exposure bias is introduced.
- DSR improves generated tokens’ diversity and fluency while avoiding unnecessary repetitions.
BERTScore
BERTScore: Evaluating Text Generation with BERT BERTSCORE computes a similarity score for each token in the candidate sentence with each token in the reference sentence. However, instead of exact matches, they compute token similarity using contextual embeddings. In another word, BERTSCORE focuses on sentence-level generation evaluation by using pre-trained BERT contextualized embeddings to compute the similarity between two sentences as a weighted aggregation of cosine similarities between their tokens. BERTScore has a higher correlation with human evaluation on text generation tasks comparing to the existing evaluation metric 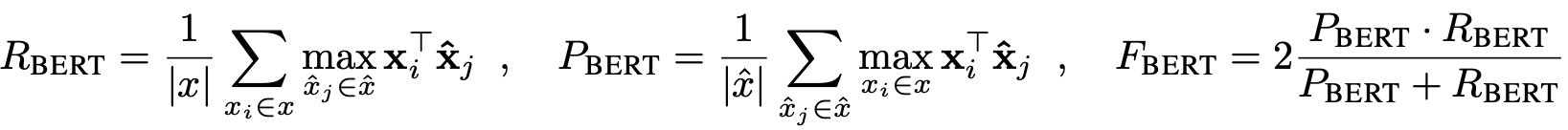
- Advantages: BERTSCORE addresses two common pitfalls in n-gram-based metrics such as BLEU, ROUGE, and METEOR.
- First, such methods often fail to robustly match paraphrases. This leads to performance underestimation when semantically-correct phrases are penalized because they differ from the surface form of the reference.
- Second, n-gram models fail to capture distant dependencies and penalize semantically-critical ordering changes. For example, given a small window of size two, BLEU will only mildly penalize swapping of cause and effect clauses (e.g. A because B instead of B because A), especially when the arguments A and B are long phrases.
Human Judgement, Learned Metrics
- Relevance (selection of important content from the source) - consistency (factual alignment between the summary and the source)
- Fluency (quality of individual sentences)
- Coherence (collective quality of all sentences)
- Grammer
- Information Quality
- Duplication
- Diversity
- Brevity
Models
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer, T5
Paper from Google 
With T5, authors propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. The text-to-text framework allows to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). One can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
Fidnings:
- model architectures, where they found that encoder-decoder models generally outperformed “decoder-only” language models;
- pre-training objectives, where they confirmed that fill-in-the-blank-style denoising objectives (where the model is trained to recover missing words in the input) worked best and that the most important factor was the computational cost;
- unlabeled datasets, where they showed that training on in-domain data can be beneficial but that pre-training on smaller datasets can lead to detrimental overfitting;
- training strategies, where they found that multitask learning could be close to competitive with a pre-train-then-fine-tune approach but requires carefully choosing how often the model is trained on each task;
- and scale, where they compare scaling up the model size, the training time, and the number of ensembled models to determine how to make the best use of fixed compute power.
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
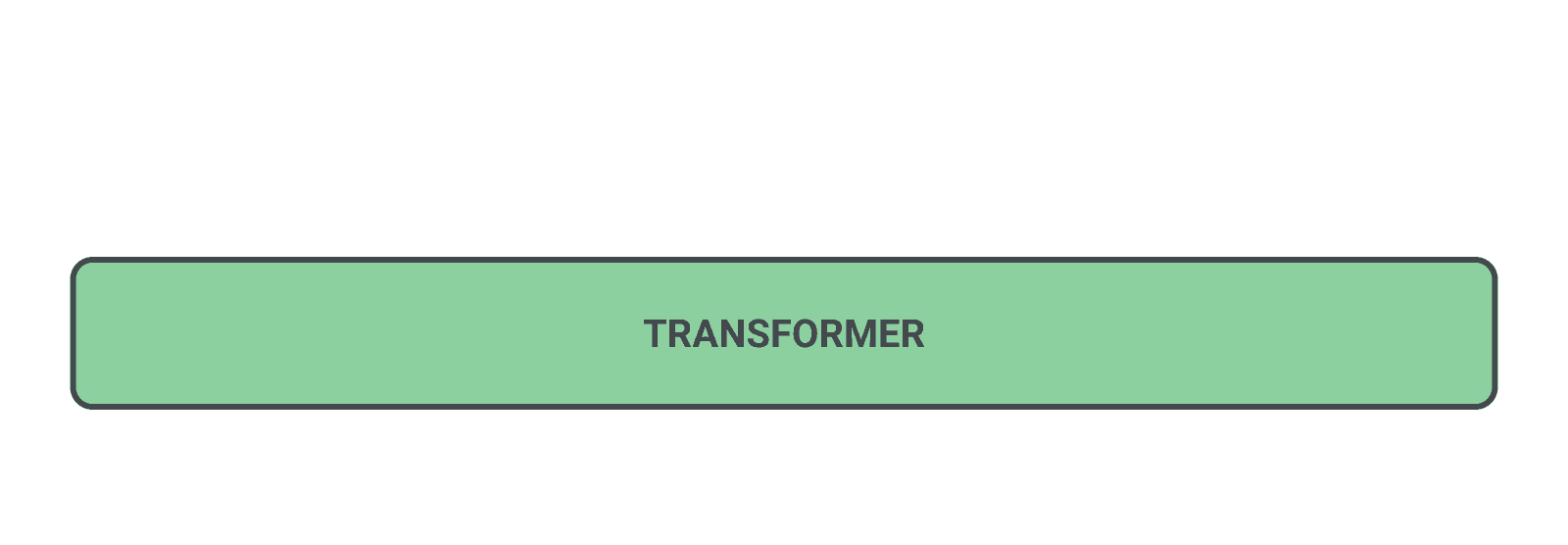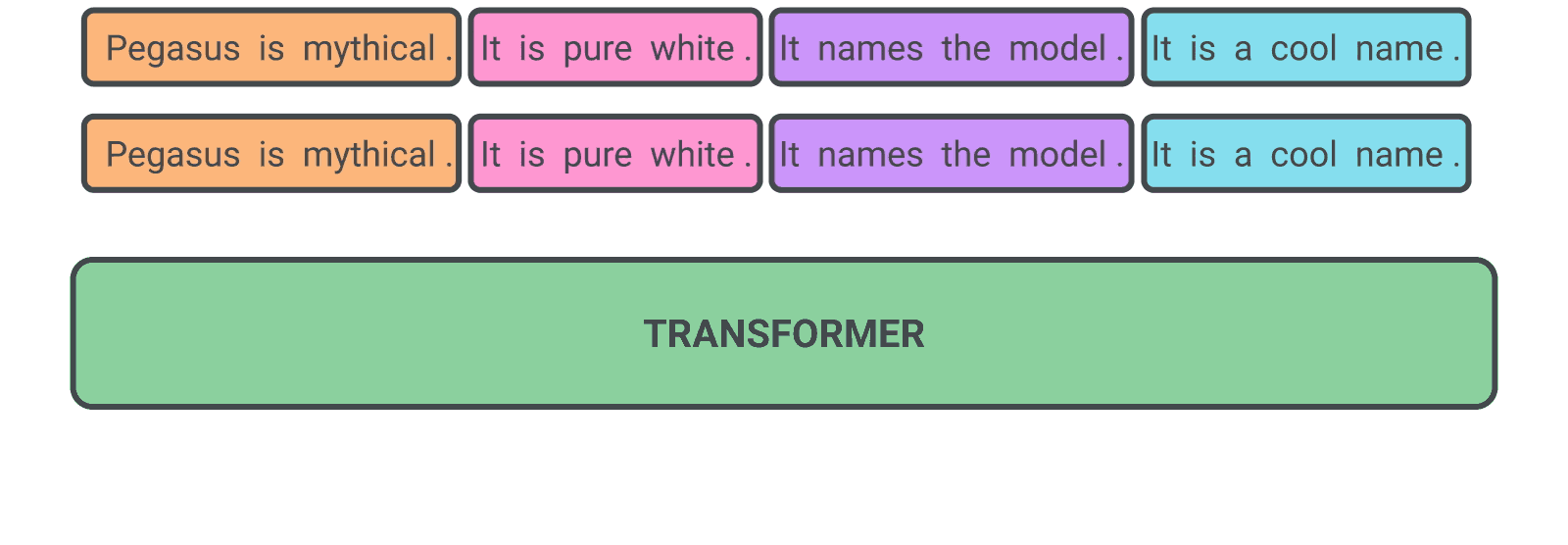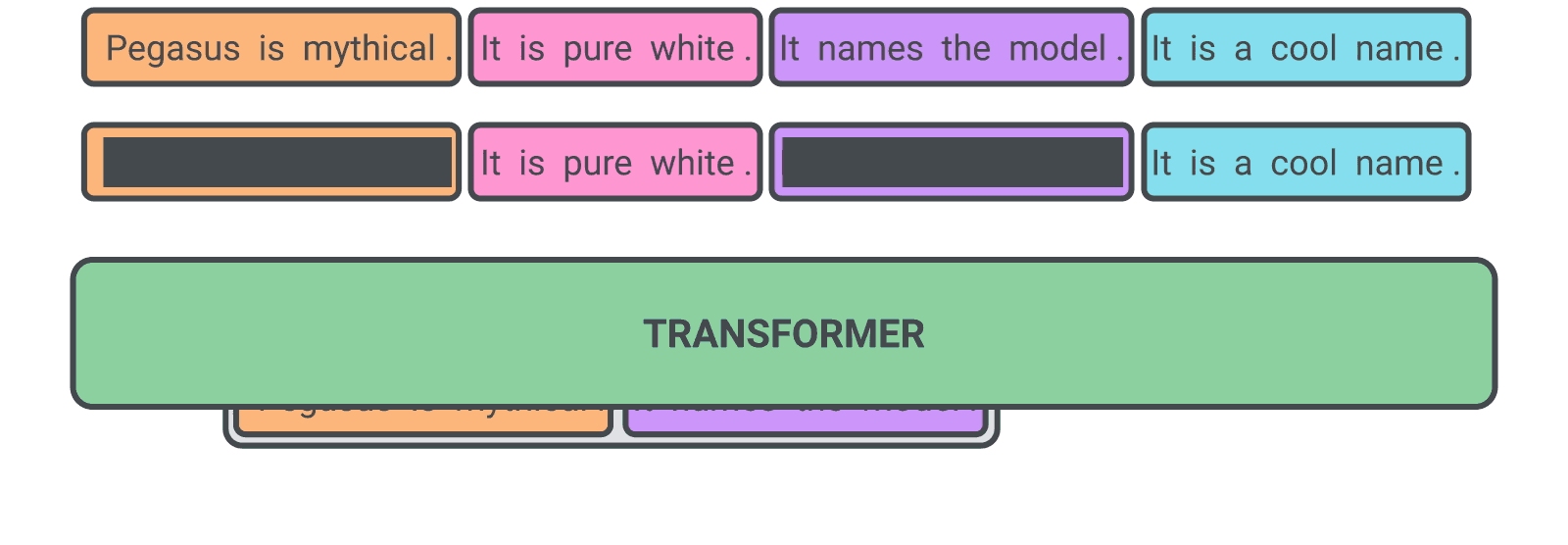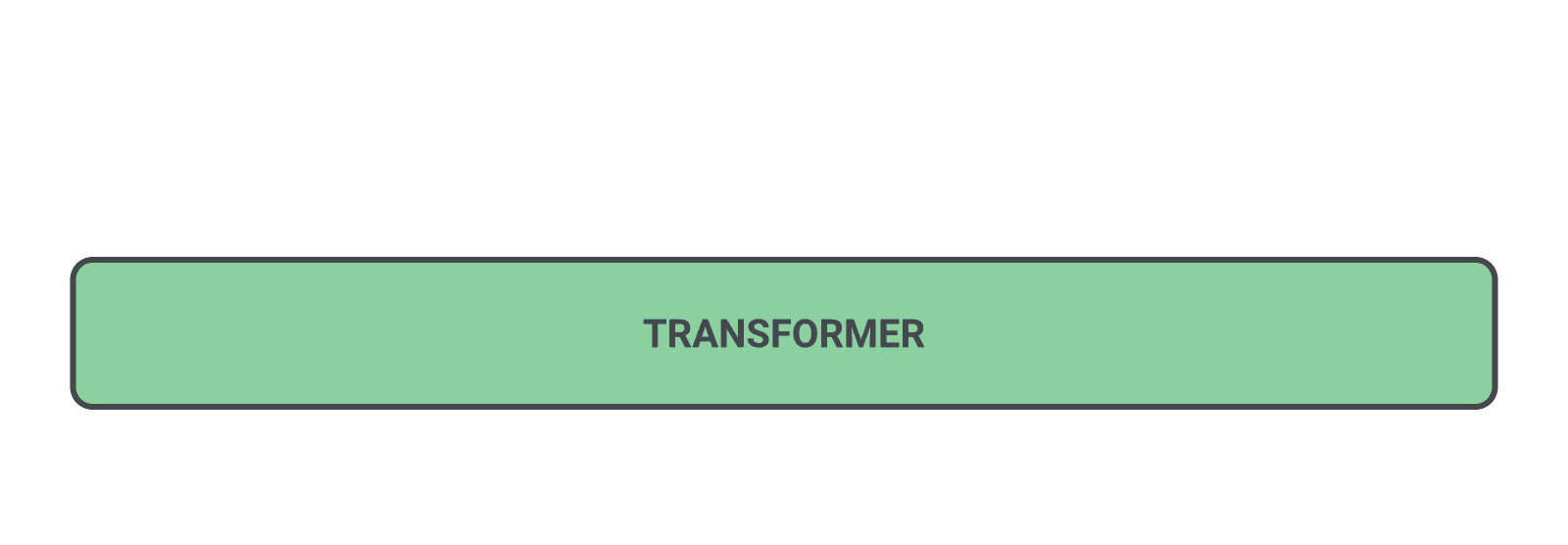
The authors designed a pre-training self-supervised objective (called gap-sentence generation) for Transformer encoder-decoder models to improve fine-tuning performance on abstractive summarization. The hypothesis is that he closer the pre-training self-supervised objective is to the final down-stream task, the better the fine-tuning performance.
In PEGASUS pre-training, several whole sentences are removed from documents and the model is tasked with recovering them. An example input for pre-training is a document with missing sentences, while the output consists of the missing sentences concatenated together. This is an incredibly difficult task that may seem impossible, even for people, and we don’t expect the model to solve it perfectly. However, such a challenging task encourages the model to learn about language and general facts about the world, as well as how to distill information taken from throughout a document in order to generate output that closely resembles the fine-tuning summarization task. The advantage of this self-supervision is that you can create as many examples as there are documents, without any human annotation, which is often the bottleneck in purely supervised systems.
The authors found out that choosing “important” sentences to mask worked best, making the output of self-supervised examples even more similar to a summary. They automatically identified these sentences by finding those that were most similar to the rest of the document according to ROUGE metric. Similar to T5, the model is pre-trained on a very large corpus of web-crawled documents, and then fine-tunedd on 12 public down-stream abstractive summarization datasets, resulting in new state-of-the-art results as measured by automatic metrics, while using only 5% of the number of parameters of T5. The datasets were chosen to be diverse, including news articles, scientific papers, patents, short stories, e-mails, legal documents, and how-to directions, showing that the model framework is adaptive to a wide-variety of topics.